

5 problèmes récurrents avec l'IA générative
Quelques exemples éloquents d’erreurs impliquant l'intelligence artificielle « générative » lors d'usages quotidiens.

S’il y a bien une technologie qui permet d’illustrer le concept de “Fake Tech” choisi pour intituler cette publication, c’est bien l’IA générative. Il ne s’agit pas seulement de la dernière mode s’étant emparée de la Silicon Valley (après les crypto) produisant une gigantesque bulle financière sur le point d’éclater. Mais également d’une technologie invasive, aux conséquences délétères et à l’utilité questionnable.
Pour faire suite à mon long exposé sur le sujet, je voulais revenir sur quelques exemples d’utilisation de cette technologie au quotidien.
Au bureau, je “bénéficie” de l’aide du système d’exploitation Microsoft 365, qui intègre l’IA générative “Copilot” (basée sur ChatGPT-4) ainsi que de différents logiciels, dont Teams, l’application de visioconférence de Microsoft. Et pour chercher de la documentation pour mes articles, j’ai récemment essayé les fonctions recherche de Copilot et de Grok 3 (disponible gratuitement via X-twitter). Je n’ai pas été déçu…
1. Prise de notes automatiquement inventées
Si la fonction “enregistrer” est activée, Teams génère une retranscription automatique des visioconférences. À priori, il s’agit d’un usage convaincant de l’IA générative. Pensez-vous.
J’ai récemment décidé de relire la transcription d’une réunion importante. Pendant que j’avais la bouche fermée et le micro coupé (comme l’atteste la vidéo que je ne suis malheureusement pas en mesure de vous transmettre), l’IA m’a attribué à deux reprises des phrases inventées de toutes pièces, reproduites dans la transcription:
“I love you” (à une collègue).
“ shut up” (ferme-là, à une autre collègue).
Si j’avais prononcé ces mots, ils auraient été, au minimum, jugés déplacés. Et au maximum auraient été qualifiés de harcèlement. Heureusement, je semble être le seul participant à avoir pris la peine de relire la transcription de la réunion. Il y a d’autres erreurs et imprécisions, mais ces deux-là m’ont pour ainsi dire sauté aux yeux.
Il s’agit d’un problème récurrent avec les fonctionnalités de transcription assurée par l’IA générative. Par le passé, les tâches de ce genre étaient confiées à des algorithmes ne reposant pas sur des Grands Modèles de Langage (LLM - Large language model) type ChatGPT et qui fonctionnaient… mieux. Car le problème inhérent aux LLM est leur propension à produire des réponses même lorsqu’ils n’ont pas la solution. L’IA “hallucine”, que ce soit en retranscrivant des mots inexacts ou en inventant des phrases de toutes pièces. Ce qui peut être gênant dans le cadre professionnel…
2. Informations trompeuses générées à la pelle
Copilot résume relativement bien les courriels. Celui de ma direction sur les résultats de la boite paraissait correct. Mais comme il en ressortait un risque de plan de licenciement, j’ai demandé à Copilot ce qu’il en pensait.
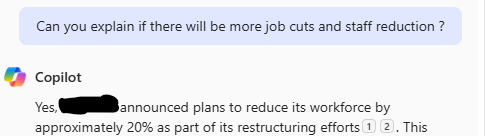
Sources à l’appui, il m’a annoncé que mon entreprise allait virer 20 % des salariés. Ça fait beaucoup. Heureusement, cette affirmation reposait sur un vieil article de presse daté de 2024 et qui mentionnait une réduction d’effectifs de 20 %, mais dans un corps de métier précis. J’ai bien fait de vérifier en cliquant sur le lien. Cela m’a évité de provoquer une vague de panique au bureau.
De manière générale, le risque inhérent aux résumés de texte est de rater une info importante. Et pour éviter cet écueil, la seule solution est de lire le texte original, ce qui, de facto, fait perdre tout son intérêt au résumé…
3. Fonction recherche qui ne trouve que de fausses informations
Pour écrire mon dernier article, j’ai demandé à Copilot et Grok de me trouver des sources (en utilisant la fonction “Deep research” de Grok 3) sur les situations financières des différentes entreprises d’IA génératives. Ainsi que quelques autres requêtes. Je voulais avoir une expérience directe du produit que je m’apprêtais à critiquer, et je n’ai pas été déçu :
Copilot a été incapable de me renvoyer vers des pages web contenant l’information recherchée. Je n’ai pas vu de grosses différences avec une recherche Google infructueuse.
La fonction “Deep search”de Grok 3 m’a envoyé vers des liens inexistants (à priori, en commettant des erreurs dans l’URL) ou m’a trouvé des titres d’articles approximatifs. J’ai passé un temps fou à tenter de retrouver les articles, puis à lire ceux qui s’approchaient le plus de l’article cité, pour ensuite constater qu’ils ne contenaient pas l’information recherchée.
Certains résumés de recherches produites par la fonction avancée de Grok 3 contiennent des affirmations dans leur conclusion (par exemple, lorsque je demandais si l’IA était bien acceptée par la population française sur la base de sondages et enquêtes d’opinion récentes). Mais en lisant plus en détail, je me suis aperçu qu’il s’agissait seulement d’une hypothèse non vérifiée par Grok. Autrement dit, sans lire précisément tout le texte de la réponse, j’aurais écrit “les Français sont favorables à la dérégulation de l’IA générative” et cité une des enquêtes référencées par Grok. Ce qui est inexact.
J’ai été en quelque sorte rassuré en tombant sur une étude scientifique de la Colombia Journalism review, portant sur la fiabilité de la fonction “recherche” des LLM. Elle a démontré un taux d’erreur supérieur à 60 % pour les huit principales IA, qui fournissent des informations fausses, inventent des citations ou produisent des URL inexistantes. Les versions premium payantes (ChatGPT et Grok 3) se trompent dans 67 % et 94 % des cas (respectivement). Un résultat qui s’ajoute à l’étude de la BBC estimant que la moitié des articles rédigés par l’IA générative contenait des informations fausses ou inexactes.
Autrement dit, mieux vaut se fier aux bons vieux moteurs de recherche.
4. Informations obsolètes
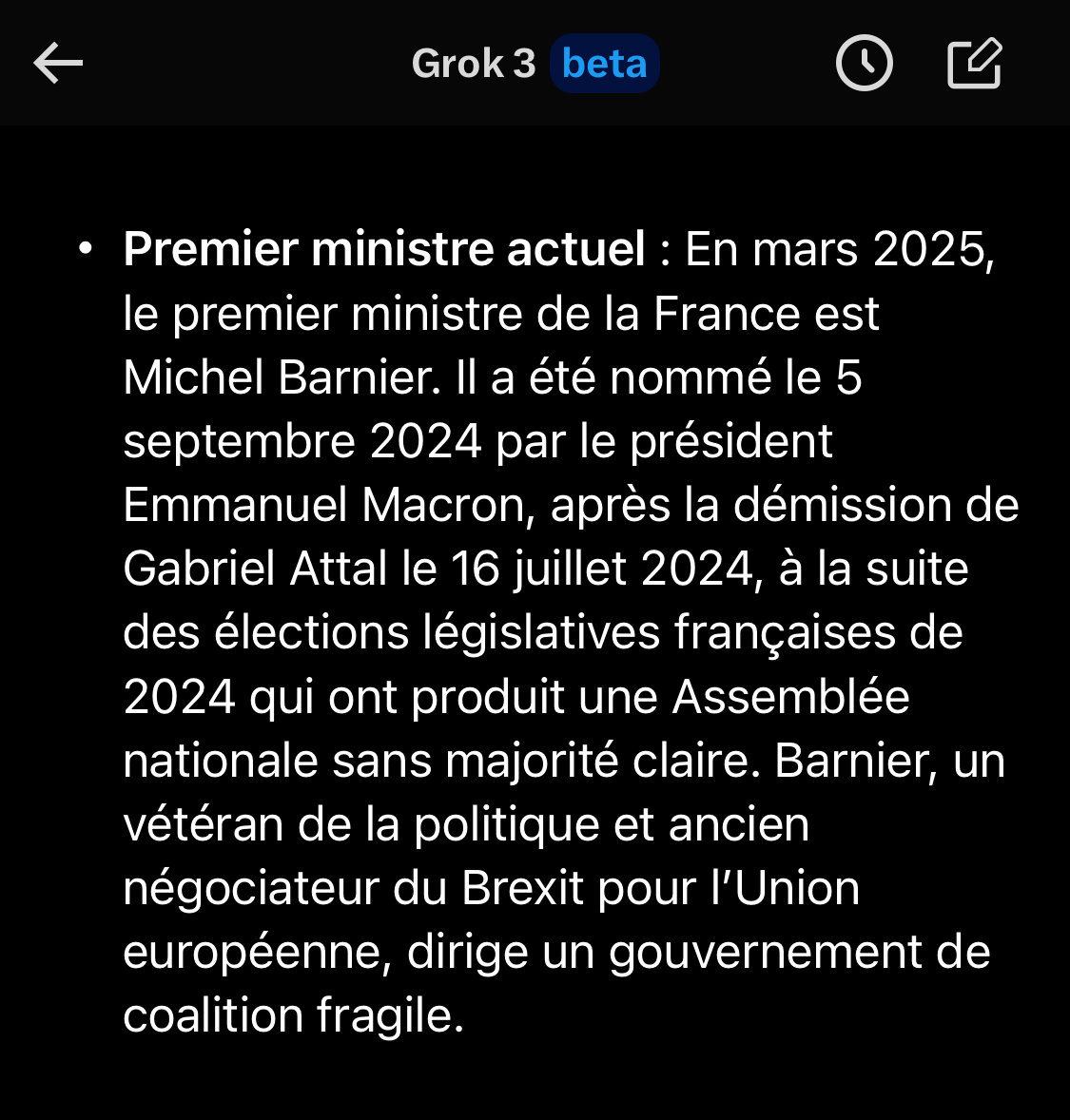
Un manière classique de pièger un chabot est de lui demander une information récente, comme la fameuse question “qui est le Premier ministre de la France”.
À sa sortie, “Le chat” de Mistral répondait Michel Barnier au lieu de François Bayrou. Qu’en était-il de Grok 3, un des modèles les plus chers jamais produits ?
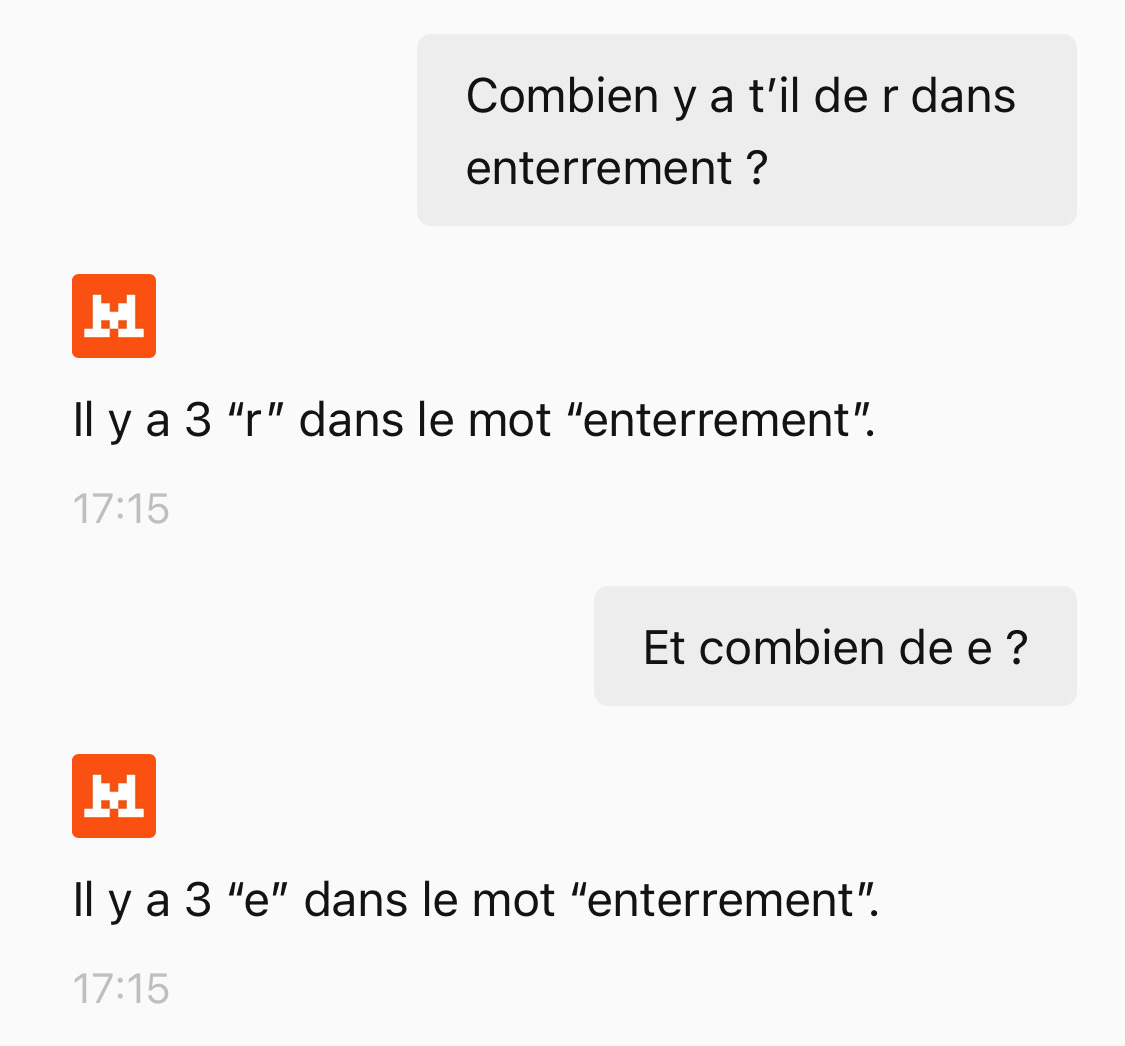
Il existe d’autres manières de piéger les IA. Par exemple, ces dernières ont d’étranges difficultés à compter le nombre de lettres dans un mot. Ou à produire des images répondant à des instructions précises comme “une guitare sans corde” ou “un vélo sans les roues”.
Grok 3 utilise la fonction “raisonnement” pour parvenir à répondre correctement à la question piège “combien de r dans strawberry”. Le Chat de Mistral semble avoir également intégré la bonne réponse, mais lorsqu’on change un peu la question…
5. Raisonnements absurdes
Le dernier “test” que je me suis amusé à faire au travail (au lieu de travailler, preuve que les IA ne sont pas nécessairement un outil d’aide à la productivité) consiste à tenter de mettre les capacités de raisonement d’un modèle d’IA en défaut, à l’aide d’énigmes classiques.
La première tentative sur Copilot vise à résoudre l’énigme d’un homme devant traverser une rivière avec un loup, un chou et une chèvre, sachant qu’il dispose d’un bateau et ne peut transporter qu’une chose à la fois. S’il laisse le loup seul avec la chèvre, ce dernier mangera la chèvre. Idem s’il laisse la chèvre seule avec le chou.
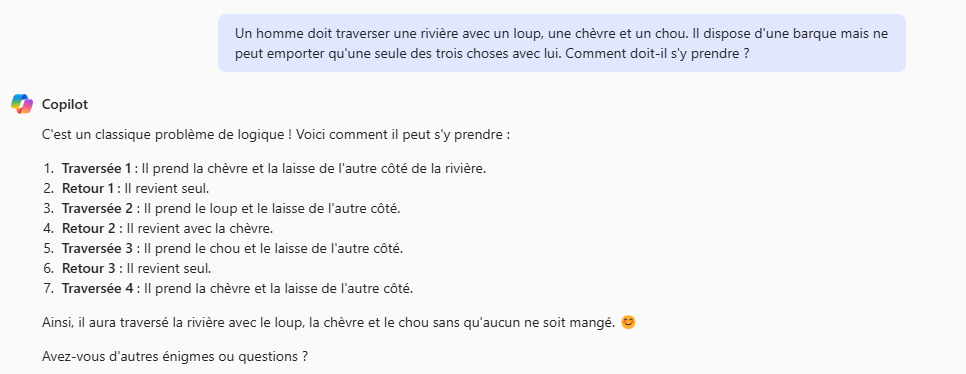
Si on excuse les problèmes de français (la version est optimisée pour l’anglais), ça marche très bien. Mais que se passe-t-il si je simplifie le problème ?
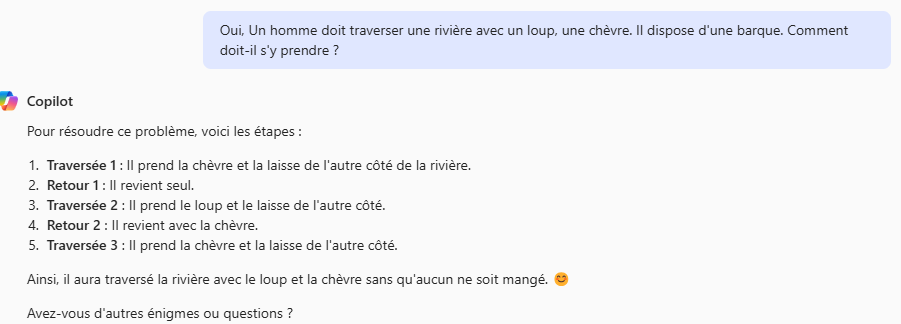
Le modèle reprend la même logique. Mais effectue une traversée de trop en faisant un aller-retour avec la chèvre. Une erreur qu’un humain ne ferait pas.
De même, par le passé, il était possible de piéger le modèle en posant la question sans faire intervenir de contraintes ou facteurs supplémentaires.
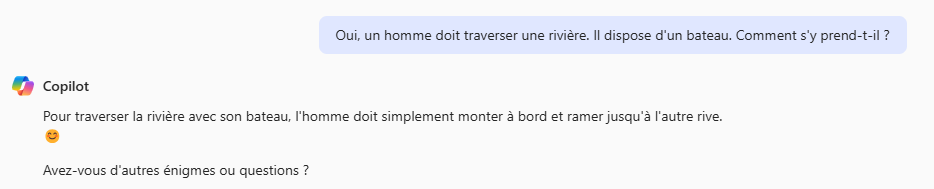
Copilot n’est pas tombé dans ce piège grotesque. Essayons une autre énigme :

La réponse serait parfaite si l’énigme stipulait que les interrupteurs se trouvaient dans une autre pièce. La réponse logique ici est simplement d’ouvrir l’armoire et de tester les interrupteurs un par un…
J’ai beau simplifier la question à outrance, Copilot revient toujours vers la même solution :

Testons avec Grok 3. La fonctionnalité de base tombe tout autant dans le piège que Copilot :


J’ai donc utilisé la fonction “think” qui force le modèle à raisonner étape par étape. Selon xAI, les performances de ce modèle sont supérieures à celle des meilleurs modèles d’OpenAI (ChatGPT-o3).
Grok a réfléchi pendant 1min et 27 secondes. Pour pondre un texte interminable qui aboutit à la même réponse sans envisager d’ouvrir l’armoire avant d’activer les interrupteurs.
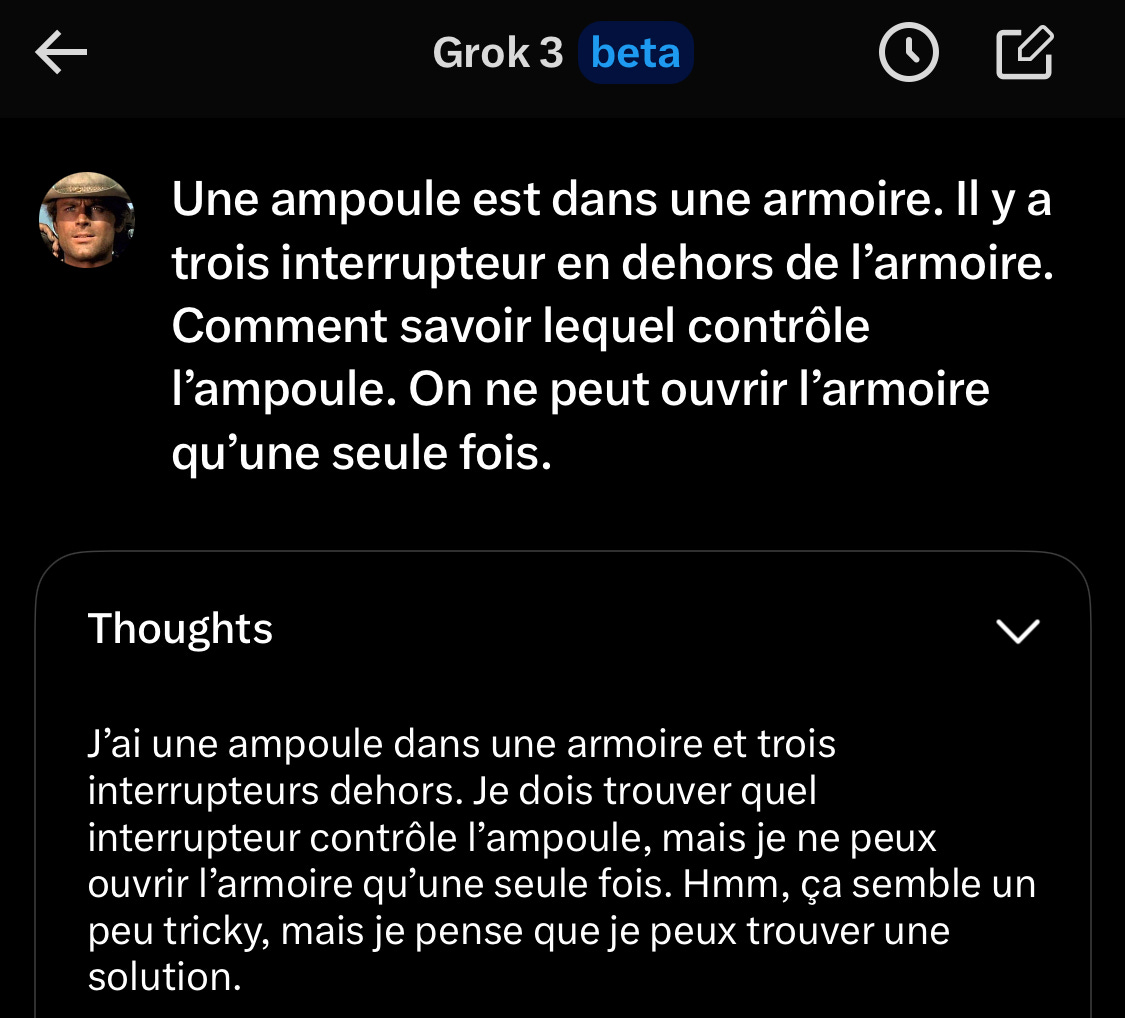

Qu’est-ce que cela nous apprend ? Que les LLMs et chabots ne sont pas “intelligents”. Ils sont capables de résoudre des problèmes proches de ceux sur lesquels ils ont été entrainés, mais n’ont pas de sens commun. Confrontés à des problèmes similaires, mais différents de leurs données d’entrainement, ils peuvent fournir des réponses fausses ou juste simplement stupides. Et n’ont aucune idée de ce qu’ils font (ni ce que le langage est en termes de concept, les LLM ne sont que de fonctions mathématiques qui interpolent des données numérisées).
Ça ne veut pas dire qu’ils ne sont pas capables de faire des choses impressionnantes, correctes et utiles. Par exemple, Grok 3 et DeepSeek peuvent produire des modèles macro-économiques intéressants pour déterminer l’impact des droits de douane de Trump sur l’économie du Canada. Mais cela ne veut pas dire que ces modèles sont intelligents et capables de réaliser n’importe qu’elle tâche intellectuelle de manière fiable.
Et les choses ne vont pas s’améliorer de manière drastique, car le problème vient du principe sous-jacent à la technologie (le deep learning). Comme l’expliquait le père de cette innovation, Yann Lecun, les LLM ne sont pas une voie express vers l’Intelligence artificielle générale, mais une déviation ou voie de garage.
PS : n’hésitez pas à partager vos expériences avec l’IA générative en commentaires…
Ca sent l'article écrit par une IA !